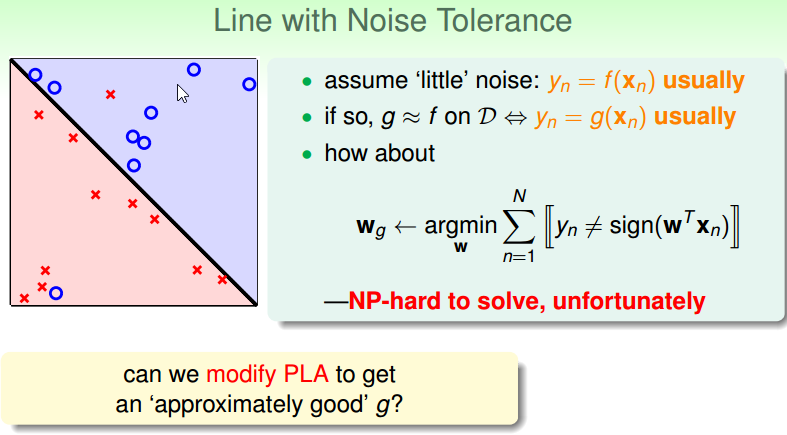
When can machines learn? (illustrative + technical)
机器学习的过程就是 learning algorithm A 从两个输入:数据 data 以及算法集合 hypothesis set 中找到一个 hypothesis g,使得 g 与真实的 target function f 最接近,这节课的重点就是学习一个具体的 hypothesis H。
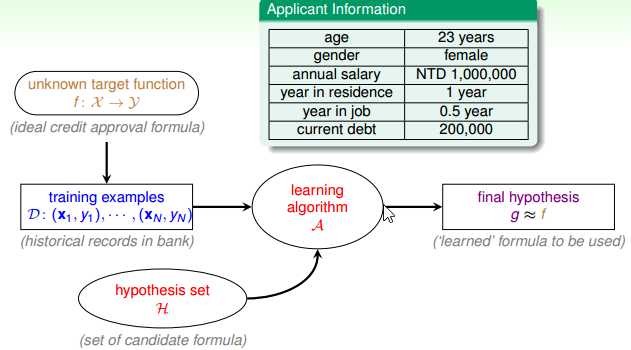
Perceptron hypothesis set
一个简单的 Hypothesis Set: Perceptron: 如果决定授权信用卡,则 h(x) = +1, 如果不授权信用卡,则 h(x) = -1.

从上图中可以明显看出,一个具体的 h,与各个权重 w 以及设定的阈值 threshold 有关。这样的 h 在历史上被称作感知器 perceptron。这些字的来源由早期研究类神经网络而来。
其向量的表示为:

以2维的向量为例,h 的具体样子为:

从几何的角度讲,感知器 perceptron 实际上就是平面上的一条条线,因此又被称作 linear classifiers。即:
perceptron <=> linear classifiers
perceptron learning algorithm (PLA)
上一节,我们了解了一个可能的 H 的样子,也就是平面上所有的线(或者是高维空间里面的一个平面)。现在的问题是,如何设计一个算法,从所有的线 H 里面选出一条最好的线出来。
一条最好的线 g 的定义就是让 g ≈ f,但是难点在于 f 是未知的。唯一可以确定的是 data 是从 f 中产生的。所以,可以先让 g 在看过的 data 里面与 f 越接近越好,或者最好是一模一样(个人注释:over fitting)。
接下来就是在已经看过的数据 data 里面找一条线,这条线要能够正确的将 data 分开。难点在于 H 是无限的。
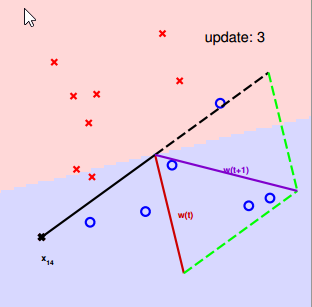
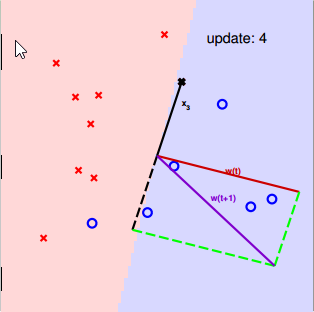
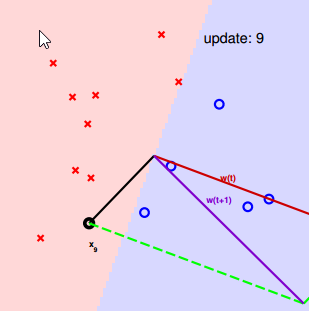
所以解决的方式是,任意找一条线,然后再依次去修正它(稍微移动一下)。

下面使用线的权重 w 来表示一条线,具体的算法过程为:
从 w0 开始,找到在数据 D 中分类错误的点(xn, yn),即:
For t = 0,1,2…:
找到一个 wt 分类错误的点 (xn(t), yn(t)): sign(wTt) ≠ yn(t)
修正这个错误通过:wt+1 <– wt + yn(t)Xn(t)
一直修正到所以的数据都分类正确了。
修正的方法有两种:
- 一种是想要的符号是正的,结果是负的:这种情况表明, W 与 X 的角度过大(超过90度了),因此修正方法为将 W 转到 W 与 X 的中间位置上来。
- 另一种是想要的符号是负的,结果为正的:这种情况表明,W 与 X 的角度过小(小于90度了),因此修正方法为将 W 转到远离 X 的位置上去。

本质上, W 为分类器(直线) 的法向量:
修正的过程为:
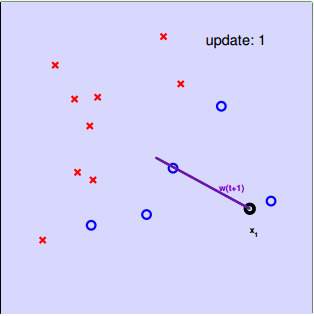
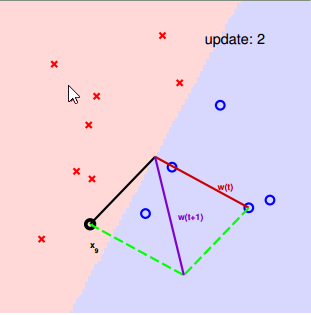

两个问题:
- 修正的过程一定停下来吗?
- 停下来的线是 g ≈ f 吗?
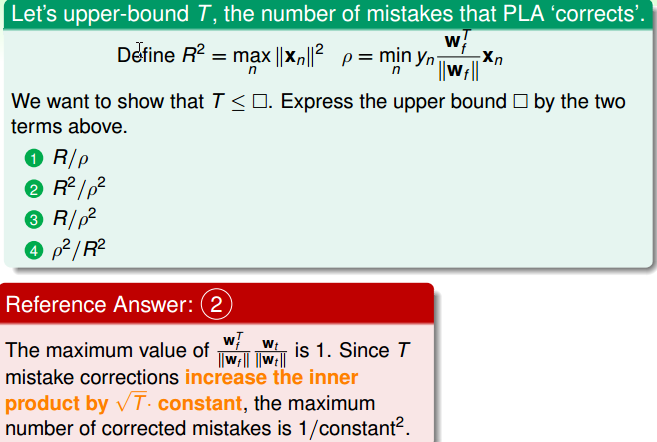
Guarantee of PLA
PLA 停下来的条件:数据线性可分。
思考:假设数据D线性可分(linear separable),PLA一定会停下来吗?
Wf:表示真实的线
Wt:表示调整的线
衡量Wt和Wf很接近,可以对两条线做内积。内积越大,两条线越接近。
即:linear separable D <=> 存在 Wf 使得:yn = sign(wTfxn)

还要处理向量长度的问题:

Non-Separable data
- 线性可分表明:Wt 和 Wf会越来越接近。
- 用错误修正表明:Wt 的长度会缓慢成长。
如果数据D并不是线性可分怎么办?
最好的分割线:在数据 D 上,犯错误最小的线。
贪心算法:新的线与旧的线进行对比。