前言
Hive 是 Hadoop 生态系统中必不可少的一个工具,它提供了一种 SQL 语言,可以查询存储在 Hadoop 分布式文件系统(HDFS)中的数据或其他和 Hadoop 集成的文件系统, 如 MapR-FS,Amazon的S3和像 HBase(Hadoop数据库) 和 Cassandra 这样的数据库中的数据。
第1章 基础知识
搜索引擎公司、电子商务公司、社交网络等许多组织意识到他们所收集的数据是让他们了解他们的用户,提高业务在市场上的表现以及提高基础架构效率的一个宝贵的资源。
Hive提供了一个被称为 Hive 查询语言(HiveQL 或 HQL)的SQL语言,来查询存储在 Hadoop 集群中的数据。Hive 可以将大多数的查询转换为MapReduce任务(job),进而在介绍一个令人熟悉的 SQL 抽象的同时,拓宽 Hadoop 的课扩展性。
Hive 的劣势:
- Hive 不支持记录级别的更新,插入或者删除操作。
- 因为Hadoop是一个面向批处理的系统,而MapReduce任务(job)的启动过程需要消耗较长时间,所以 Hive 查询延时比较严重。
- Hive 不支持事务。因此,Hive 不支持OLTP(联机事务处理)所需的关键功能。
如果用户需要对大规模数据使用OLTP功能的话,那么应该选择使用一个NoSQL数据库,例如,和 Hadoop 结合使用的 HBase 及 Cassandra。
Hadoop 和 MapReduce 综述
参考Tom White 《Hadoop权威指南》一书。
MapReduce
MapReduce是一种计算模型,该模型可以将大型数据处理任务分解为很多单个的,可以在服务器集群中并行执行的任务,这些任务的计算结果可以合并在一起来计算最终的结果。
MapReduce编程模型由谷歌开发,两篇经典的论文为:《MapReduce: 大数据之上的简化数据处理》,以及《Google 文件系统》。这两篇论文启发了道-卡丁开发了 Hadoop。
MapReduce这个术语来自于两个基本的数据转换操作: Map过程和reduce过程。MapReduce 计算框架中的输入和输出的基本数据结构是键-值对。
下图介绍了一种 Word Count程序,左边的每个 Input(输入) 框都表示一个单独的文件,默认情况下,每个文档都会触发一个 Mapper 进程进行处理。而在实际场景中,大文件可能会划分为多个部分,每个部分都会被发送给一个 Mapper 进行处理。同时,也有将多个小文件合并为一个部分供某个 Mapper进行处理。
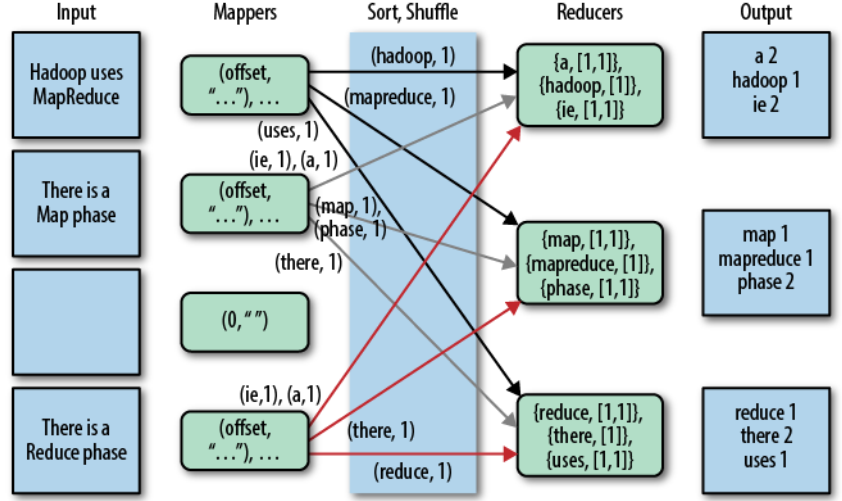
Hadoop 神奇的地方一部分在于后面要进行的Sort和Shuffle过程,Hadoop会按照键来对键-值进行排序,然后Shuffle,将所有具有相同键的键-值对分发到同一个Reducer中。这里有很多方式可以决定哪个Reducer获取哪个范围内的键对应的数据。
Hadoop生态系统中的Hive
下图显示了Hive的主要模块,以及Hive是如何与Hadoop交互工作的。有好几种方式可以与Hive进行交互,例如命令行。或者图形界面:Karmasphere发布的一个商业产品,Cloudera提供的开源 Hue 项目,以及 Qubole 提供的 “Hive即服务”。
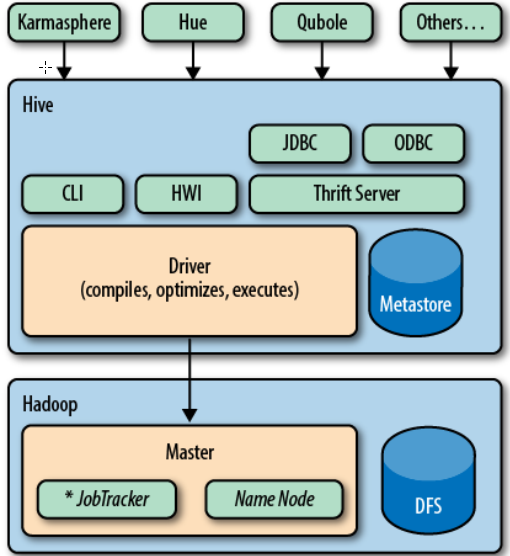
Hive 发行版中附带的模块有CLI(命令行),一个称为 Hive 网页界面(HWI)的简单网页界面,以及可通过 JDBC、ODBC 和一个 Thrift 服务器进行编程访问的几个模块。
所有的命令和查询都会进入到Driver模块,通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤执行(通常是启动多个MapReduce任务(job)来执行)。当需要启动 MapReduce job 时,Hive本身是不会生成 Java MapReduce 算法程序的。相反,Hive 通过一个表示 “job执行计划”的XML 文件驱动执行内置的、原生的 Mapper 和 Reducer 模块。
Hive通过和 JobTracker通信来初始化 MapReduce任务(job),而不必部署在 JobTracker 所在的管理节点上执行。
Metastore(元数据存储)是一个独立的关系型数据库(通常是一个MySQL实例),Hive 会在其中保存表模式和其他系统元数据。
Pig
Hive的替代工具中最有名的就是 Pig,假设用户的输入数据具有一个或者多个源,而用户需要进行一组复杂的转换来生成一个或者多个输出数据集。如果使用 Hive, 用户可能会使用嵌套查询,但是在某些时刻会需要重新保存临时表来控制复杂度。
Pig被描述为一种数据流语言,而不是一种查询语言,因此,Pig常用于ETL(数据抽取,数据转换,和数据装载)过程的一部分.
参考 Alan Gates 《Pig 编程指南》
HBase
如果用户需要 Hive 无法提供的数据特性(如行级别的更新,快速查询响应时间,以及支持事务)的话,那么该怎么办呢? HBase 是一个分布式的、可伸缩的数据存储,其支持行级别的数据更新,快速查询和行级事务(但不支持多行事务)。
HBase支持的一个重要特性就是列存储,可以像键-值存储一样来使用HBase。HBase使用HDFS(或其他某种分布式文件系统)来持久化存储数据。Hive 现在已经可以和 HBase 结合使用了。
Cascading、Crunch 及其他
Java 和 Hive: 词频统计算法
统计词频:
CREATE TABLE docs (line STRING);
LOAD DATA INPATH 'docs' OVERWRITE INTO TABLE docs;
CREATE TABLE word_counts AS
SELECT word, count(1) AS count FROM
(SELECT explode(split(line, '\s')) AS word FROM docs) w
GROUP BY word
ORDER BY word;